我的LLM编程工作流:展望2026年
在AI辅助编程中保持控制权的最佳实践
Addy Osmani,2025年12月18日
概述
AI编程助手已经成为改变游戏规则的工具,但有效使用它们需要技巧和结构。在Anthropic,约90%的Claude Code代码都是由Claude Code自己编写的。然而,使用LLM进行编程是”困难且不直观的”,需要学习新的模式。关键是将LLM视为强大的结对程序员,需要清晰的方向、上下文和监督,而不是自主判断。
从清晰的计划开始
不要只是向LLM抛出愿望——首先要定义问题并规划解决方案。
第一步是与AI一起进行详细规格的头脑风暴,然后在编写代码之前概述分步计划。对于新项目,描述想法并要求LLM反复提问,直到需求和边缘情况都被详细说明。将其编译成一个全面的spec.md,包含需求、架构决策、数据模型和测试策略。
接下来,将规格输入到具有推理能力的模型中,生成项目计划,将实现分解为逻辑性的、小块的任务。这种前期投资就像”15分钟内的瀑布式开发”——一个快速的结构化规划阶段,使后续编码更加顺畅。
将工作分解为小的迭代块
范围管理就是一切——向LLM提供可管理的任务,而不是一次性处理整个代码base。

避免要求大型、单一的输出。将项目分解为迭代步骤或任务,然后逐个解决。LLM在聚焦提示下表现最佳:一次实现一个函数、修复一个bug、添加一个功能。每个块都足够小,AI可以在上下文中处理,你也能理解。
一次性要求太多会导致混乱和难以理清的”混乱局面”。解决方法是停下来,后退一步,将问题分解成更小的部分。每次迭代都会向前传递上下文并逐步增加,非常适合测试驱动开发。
提供广泛的上下文和指导
LLM的好坏取决于你提供的上下文——向它们展示相关的代码、文档和约束条件。
向AI提供所有需要的信息:它应该修改的代码、项目约束、已知陷阱和首选方法。现代工具提供了帮助——Claude可以导入整个GitHub仓库,IDE助手会自动包含打开的文件。更进一步,使用像Context7这样的MCP,或者手动复制重要的代码库部分或API文档。
专家用户强调”上下文打包”——在编码前将模型应该知道的所有内容进行”大脑转储”,包括目标、良好解决方案的示例,以及要避免的方法的警告。粘贴官方文档或小众库的README。像gitingest或repo2txt这样的工具可以将相关的代码库部分转储到文本文件中。
用注释和规则在提示中指导AI。LLM是字面主义者——它们会遵循指令,因此提供详细、情境化的指令可以最大限度地减少幻觉和偏离基础的建议。
选择正确的模型
并非所有编码LLM都是平等的——有意识地选择你的工具,不要害怕中途更换模型。
每个模型都有自己的”个性”。如果一个模型卡住了或给出平庸的输出,试试另一个。将相同的提示从一个聊天复制到另一个服务,看看它是否处理得更好。这种”模型抢椅子”游戏可以在你遇到模型盲点时拯救你。
使用最新的”专业”级模型,因为质量很重要。选择与你”气场相合”的AI结对程序员——当你与AI持续对话时,用户体验和语气会产生影响。
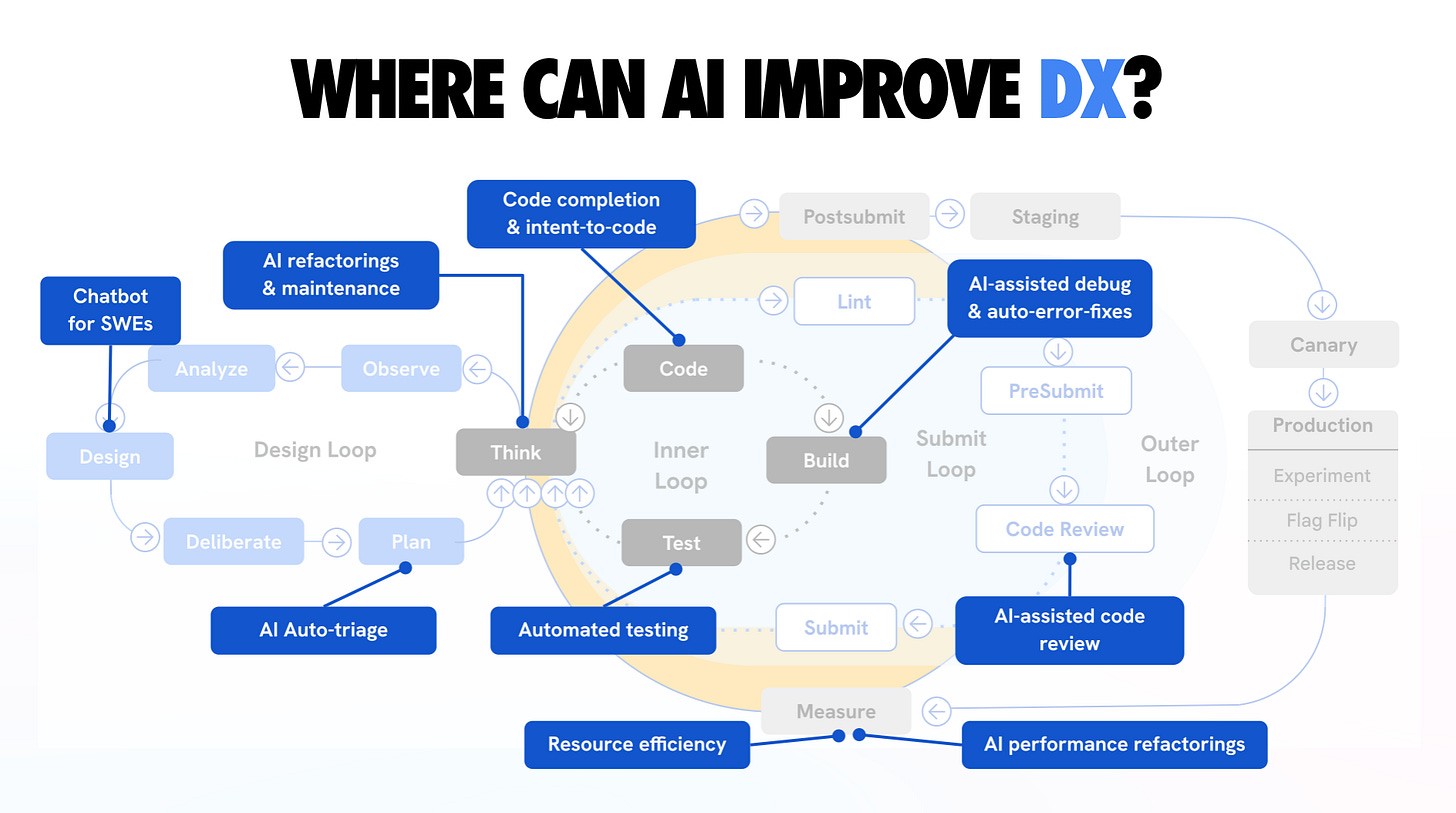
在整个生命周期中利用AI编码
通过在整个SDLC中使用特定于编码的AI帮助来增强你的工作流程。
新的AI代理出现了:Claude Code、OpenAI的Codex CLI和Google的Gemini CLI让你可以直接在项目目录中聊天——它们可以读取文件、运行测试和多步骤修复问题。像Jules和GitHub的Copilot Agent这样的异步编码代理会在后台克隆仓库到云端VM并处理任务,打开包含代码更改和通过测试的PR。
这些工具加速了机械部分——生成样板文件、应用重复更改、自动运行测试——但仍然受益于指导。在告诉代理执行之前,在上下文中提供计划或spec.md。我们还没有达到让AI无人值守地编写整个功能的阶段;以监督的方式使用它们,密切关注每一步。
像Conductor这样的编排工具可以让你并行运行多个代理处理不同的任务。一些工程师尝试同时运行3-4个代理处理不同的功能。这非常有效,但监控多个AI线程在精神上很累。
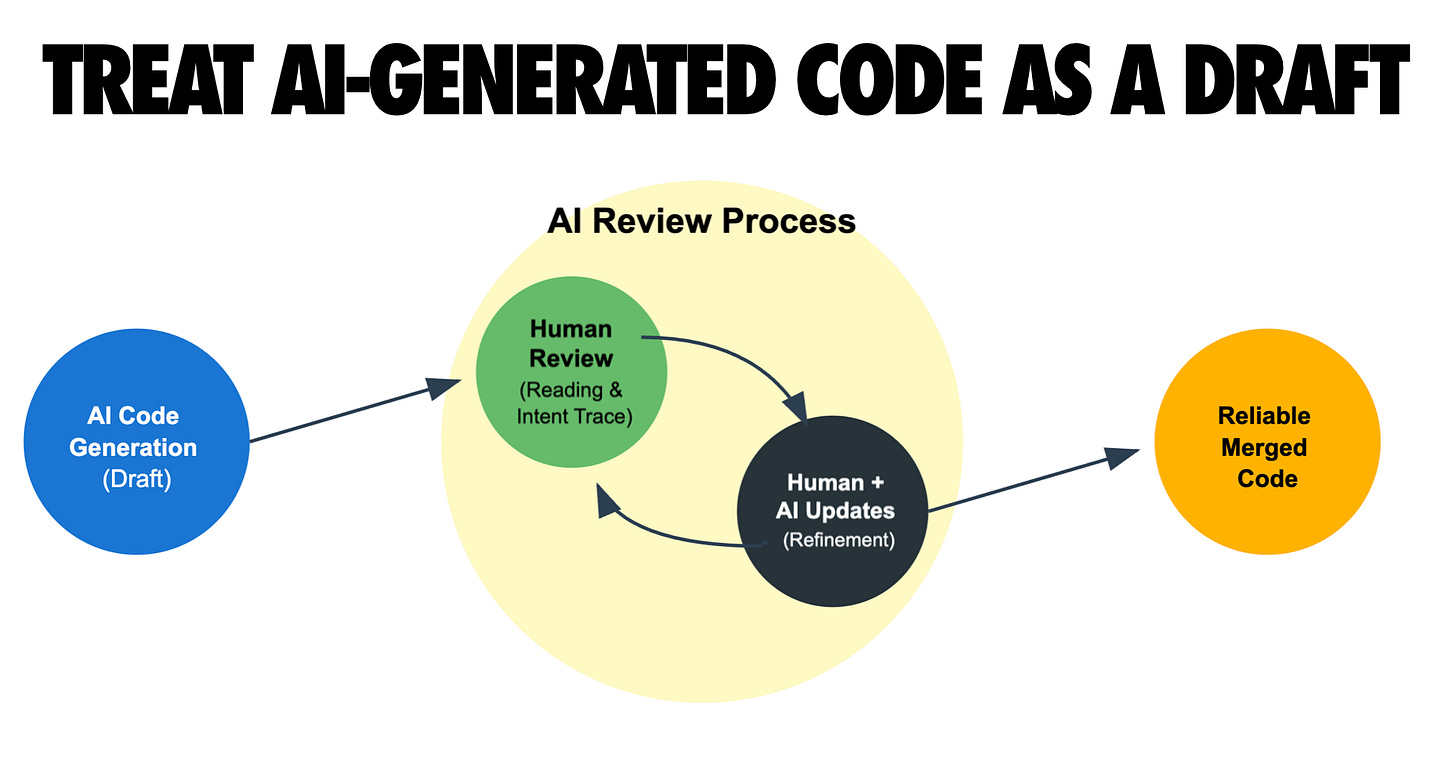
保持人在环路中
AI会愉快地产生看似合理的代码,但你对质量负责——始终彻底审查和测试。

将LLM视为”过度自信且容易犯错”的结对程序员。每个AI生成的代码片段都需要像对待初级开发人员编写的代码一样进行阅读、运行和测试。你绝对必须测试它写的内容。
将测试融入工作流程本身。为每个步骤生成测试或测试计划。指示像Claude Code这样的工具在实现任务后运行测试套件并调试失败。强大的测试实践放大了AI的实用性——没有测试,代理可能会天真地假设一切都很好,而实际上已经坏了。
进行代码审查——手动和AI辅助的。有时启动第二个AI会话来批评第一个会话产生的代码。AI编写的代码需要额外审查,因为它可能表面上令人信服,却隐藏着缺陷。
使用Chrome DevTools MCP进行调试和质量循环——它给你的代理提供了眼睛,可以看到浏览器看到的内容,检查DOM,获取性能跟踪、控制台日志和网络跟踪,用于高精度的bug诊断。
频繁提交并使用版本控制
频繁提交是你的存档点——它们让你可以撤销AI的失误并理解更改。
采用超细粒度的版本控制习惯。尽早并频繁提交,甚至比正常手工编码时更频繁。在每个小任务或成功的自动编辑后,用清晰的信息进行git提交。这创建了检查点,如果AI的下一个建议引入了bug或混乱的更改,可以回退到这些点。
适当的版本控制有助于与AI协作。由于你不能依赖AI记住所有内容(因为上下文限制),git历史成为有价值的日志。LLM可以利用提交历史——将git差异或提交日志粘贴到提示中,以便AI知道什么是新代码。
带有良好信息的提交记录了开发过程,使定位哪个提交导致问题变得更容易。使用分支或工作树来隔离AI实验——为新功能启动一个新的git工作树,以便并行运行多个AI会话而不会相互干扰。
自定义AI行为
通过提供风格指南、示例甚至”规则文件”来引导你的AI助手——一点前期调整就能产生更好的输出。

定期更新像CLAUDE.md或GEMINI.md这样的文件,包含流程规则和偏好:代码风格、lint规则、要避免的函数、函数式与OOP偏好。在会话开始时将其提供给AI,以便与约定保持一致。
使用自定义指令或系统提示设置基调。GitHub Copilot和Cursor允许你为项目全局配置AI行为。编写关于编码风格的短段落——缩进空格、箭头函数偏好、描述性变量名、ESLint要求。
提供期望输出格式或方法的内联示例。展示代码库中已有的类似函数:“这是我们实现X的方式,对Y使用类似的方法。“LLM擅长模仿——展示一两个例子,它们就会继续沿用那种风格。
在提示中添加”无幻觉/无欺骗”条款。告诉AI:“如果不确定,请寻求澄清,而不是编造答案”,以及”修复bug时始终在注释中简要解释推理。“
拥抱测试和自动化
使用你的CI/CD、linters和代码审查机器人——AI在能自动捕获错误的环境中工作得最好。
确保重度AI编码的仓库具有强大的持续集成。在每次提交或PR上运行自动化测试,强制执行代码风格检查,理想情况下提供暂存部署。让AI触发这些并评估结果。
在提示中包含linter输出。如果AI编写的代码没有通过linter,将错误复制到聊天中并说”请解决这些问题”。模型会努力纠正它。
AI编码代理越来越多地包含自动化钩子——有些在测试全部通过之前拒绝说任务”完成”。代码审查机器人作为改进的额外过滤器。
将AI与自动化结合创造了一个良性循环:AI编写代码,自动化工具捕获问题,AI修复它们,你在高层方向上进行监督。AI友好的工作流程需要强大的自动化来保持AI的诚实。
持续学习和适应
将每个AI编码会话视为学习机会——你知道得越多,AI就越能帮助你,创造良性循环。

LLM奖励现有的最佳实践——编写清晰的规格、拥有良好的测试、进行代码审查等事情在AI参与时变得更加强大。使用AI推动你提升工程水平——你变得更加严格地进行规划,并对架构更加敏感。
通过审查AI代码,你接触到新的习语和解决方案。通过调试AI错误,你加深了对语言和问题领域的理解。要求AI解释其代码或修复背后的理由——就像面试候选人一样——以获取见解。
使用AI作为研究助手:要求它枚举选项或比较库或方法的权衡。这就像拥有一位百科全书式的导师随时待命。
AI工具放大你的专业知识。它们让你从枯燥的工作中解脱出来,专注于创造性和复杂的方面。然而,对于那些没有坚实基础的人来说,AI可能导致邓宁-克鲁格效应的放大——看似构建了伟大的东西,直到它崩溃。
继续磨练你的技艺,并使用AI来加速这个过程。要有意识地定期在没有AI的情况下编码,以保持原始技能敏锐。开发者+AI的组合比单独任何一方都强大得多。
结论
随着我们进入2026年,方法本质上是”AI增强的软件工程”,而不是AI自动化的软件工程。最好的结果来自于将经典的软件工程纪律应用于AI协作——设计先于编码、编写测试、使用版本控制、维护标准。
AI编程助手是令人难以置信的力量倍增器,但人类工程师仍然是演出的导演。