多智能体系统的Context工程:从单体到协作的架构革命
引言
2025年,AI智能体正在经历一场根本性的架构变革——从单体Agent到Multi-Agent System的演进。这不仅仅是技术升级,更是思维范式的转变。正如Anthropic工程团队所展示的,多智能体架构在复杂任务上的表现比单体系统提升了90.2%。
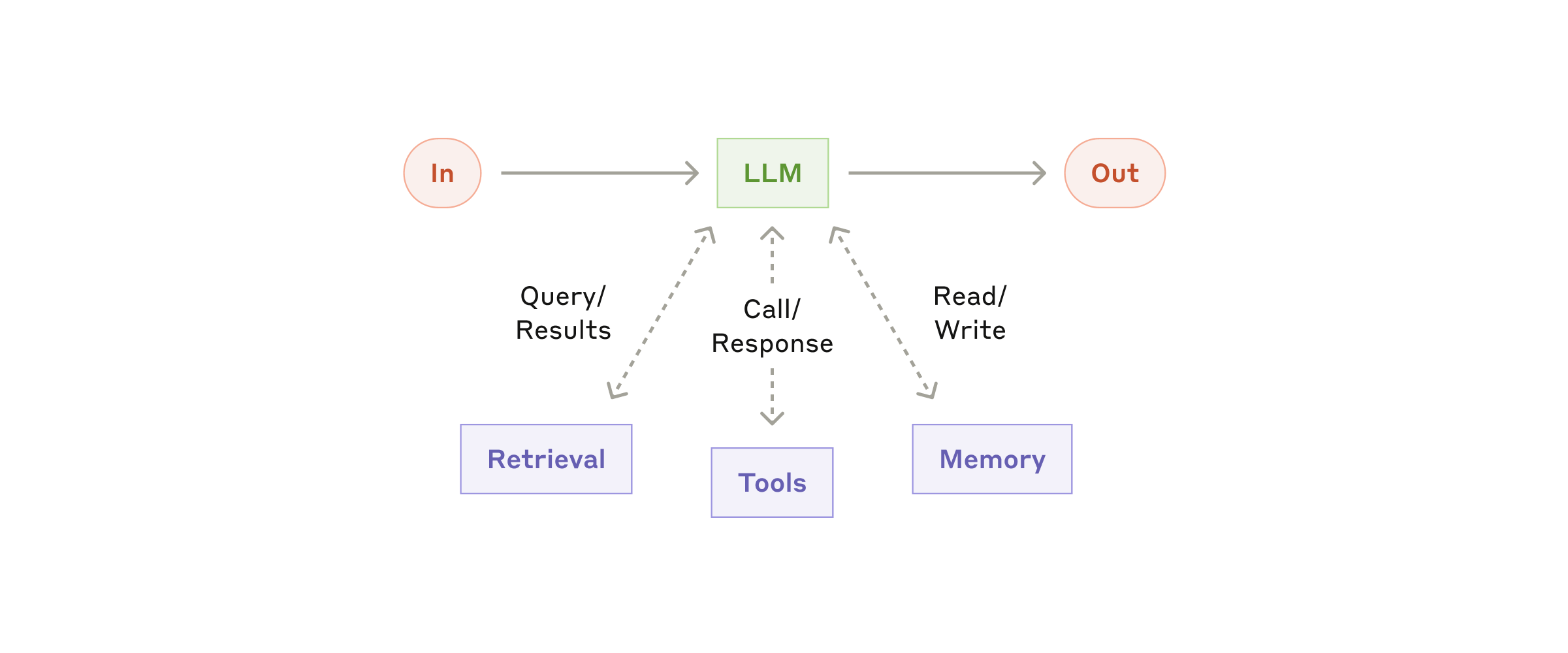 图1:增强型LLM架构 - Agent系统的基础构建块(来源:Anthropic)
图1:增强型LLM架构 - Agent系统的基础构建块(来源:Anthropic)
但这里有个关键问题:为什么大多数企业的Agent项目还是失败了?答案很简单——Context工程的缺失。本文将深入探讨如何通过先进的Context工程技术,构建真正可用的多智能体系统。
第一部分:多智能体时代的Context新挑战
从单体到协作:Context复杂度的指数级增长
传统单体Agent的context管理已经够复杂了,多智能体系统把这个复杂度提升了不止一个量级:
-
跨Agent的Context同步
- 每个Agent都有自己的工作上下文
- 需要实时同步关键信息,避免重复劳动
- 防止context冲突导致的决策矛盾
-
动态Context编排
- Lead Agent需要动态分配context给各个Sub-agent
- 根据任务进展调整context分配策略
- 保持全局context的一致性和完整性
-
Context压缩与传递
- Agent间传递信息时的智能压缩
- 保留关键信息,过滤冗余内容
- 确保压缩不会丢失语义完整性
真实案例:Anthropic的多智能体研究系统
Anthropic团队构建的研究系统充分展示了现代Context工程的威力:
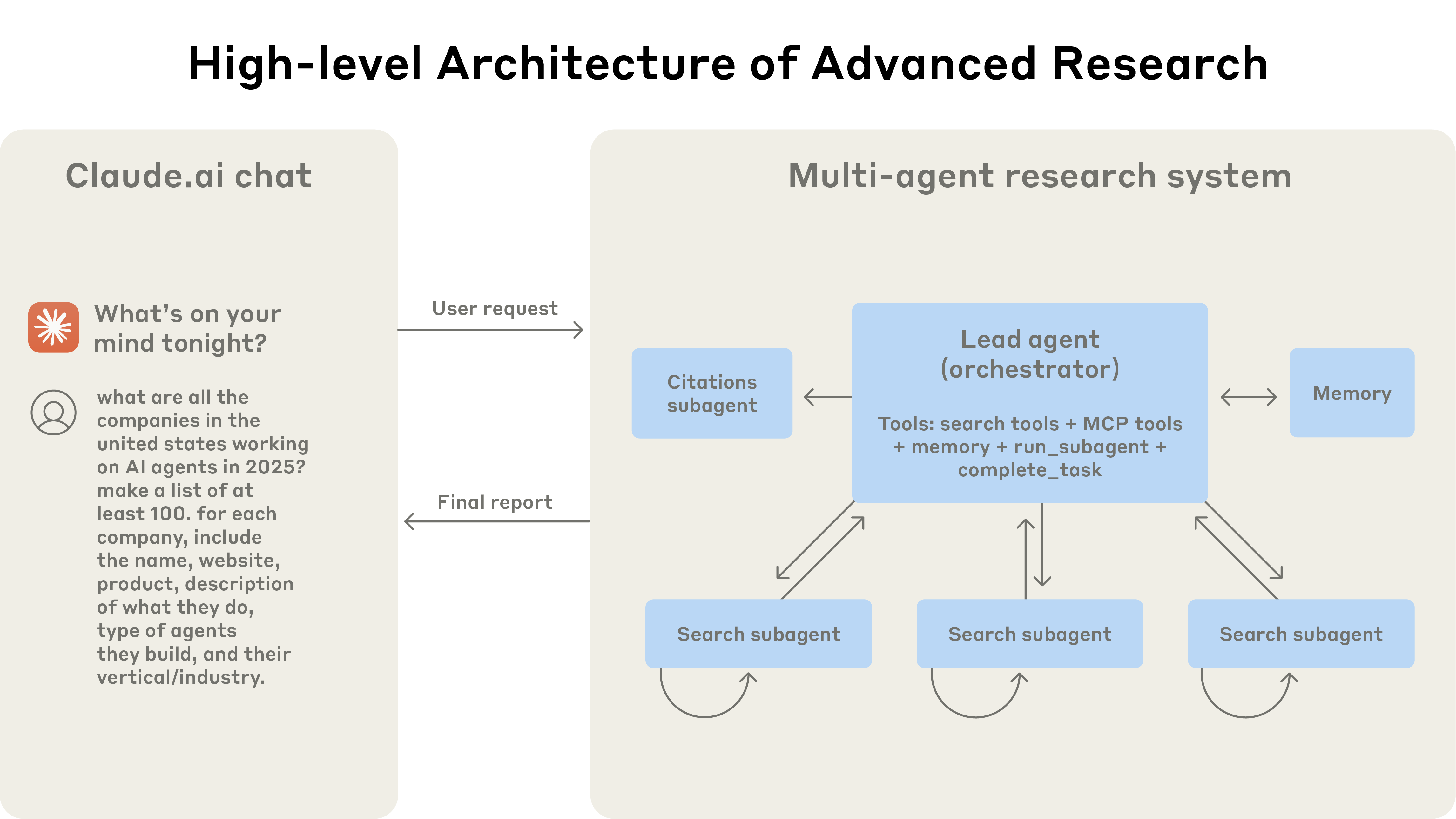 图3:Anthropic多智能体研究系统架构图(来源:Anthropic)
图3:Anthropic多智能体研究系统架构图(来源:Anthropic)
架构设计:
├── Lead Agent(协调者)
│ ├── 全局Context管理
│ ├── 任务分解与分配
│ └── 结果综合与决策
├── Sub-agents(1-10+个)
│ ├── 独立Context空间
│ ├── 专项任务执行
│ └── 结果回传机制
└── CitationAgent(引用管理)
├── 来源追踪Context
└── 引用格式化处理
这个系统最厉害的地方在于**“交错思考”(Interleaved Thinking)**机制——Agent在搜索的同时就开始评估结果,这种设计充分利用了Context的实时性。
第二部分:Contextual Retrieval——RAG系统的革命性突破
传统RAG的致命缺陷
说实话,传统RAG系统有个很大的问题:切片导致的语义丢失。当你把一个完整的文档切成小块后,每个块都失去了原本的上下文环境。
举个例子:
原文:"该公司在2023年推出了革命性产品X,市场反响热烈。"
切片后:"市场反响热烈。"
切片后完全不知道在说什么产品,这就是传统RAG的痛点。
Contextual Retrieval的创新解决方案
Anthropic提出的Contextual Retrieval通过预处理时的智能Context注入解决了这个问题:
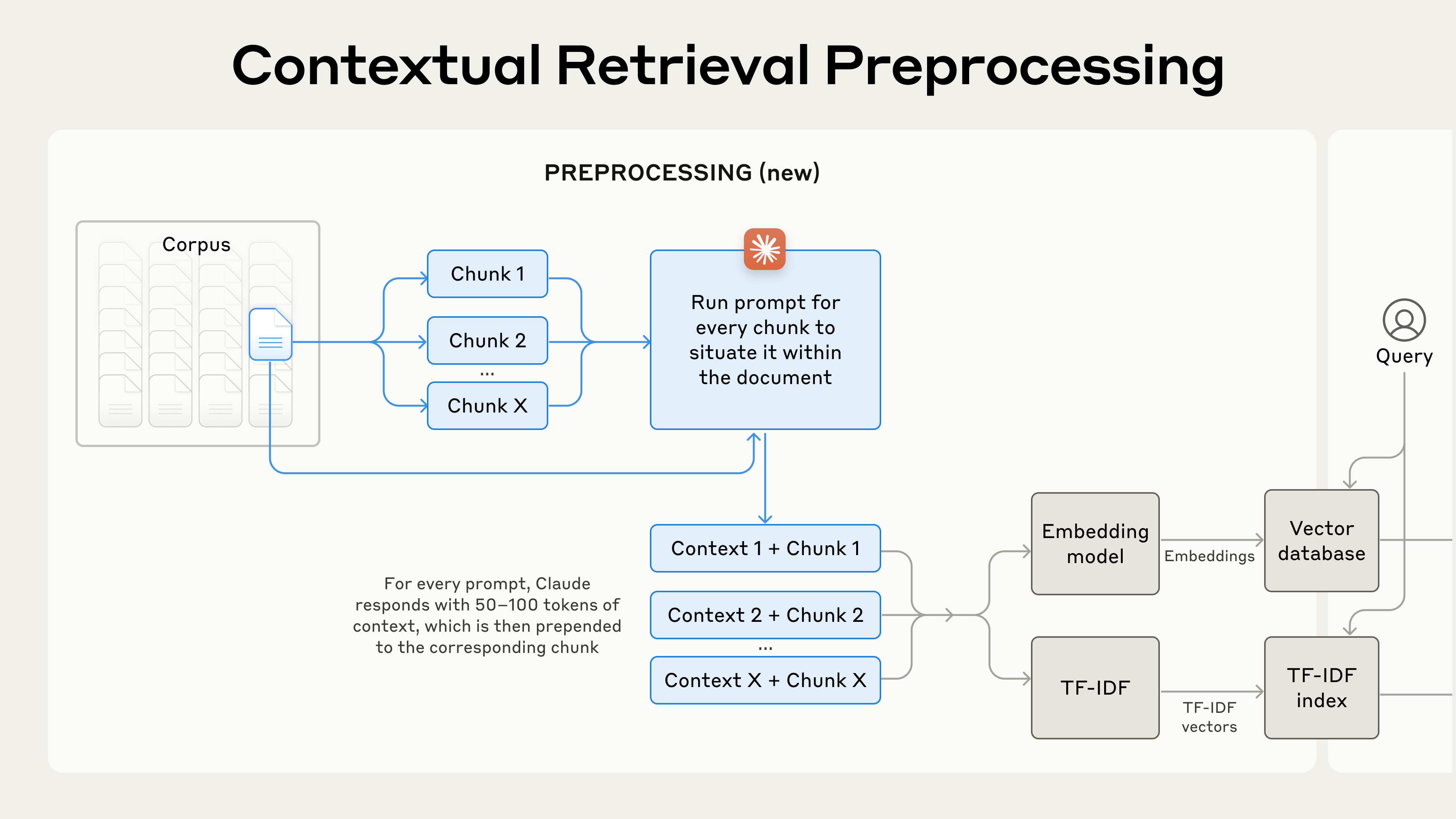 图4:Contextual Retrieval预处理工作流(来源:Anthropic)
图4:Contextual Retrieval预处理工作流(来源:Anthropic)
-
Context生成阶段
# 伪代码示例 def generate_contextual_chunk(document, chunk): context_prompt = f""" <document>{document}</document> <chunk>{chunk}</chunk> 请为这个chunk生成简洁的上下文说明... """ context = llm.generate(context_prompt) return f"{context}\n\n{chunk}" -
性能提升数据(这个真的很惊人)
- 单独使用Contextual Embeddings:失败率降低35%
- 结合Contextual BM25:失败率降低49%
- 加上重排序:失败率降低67%
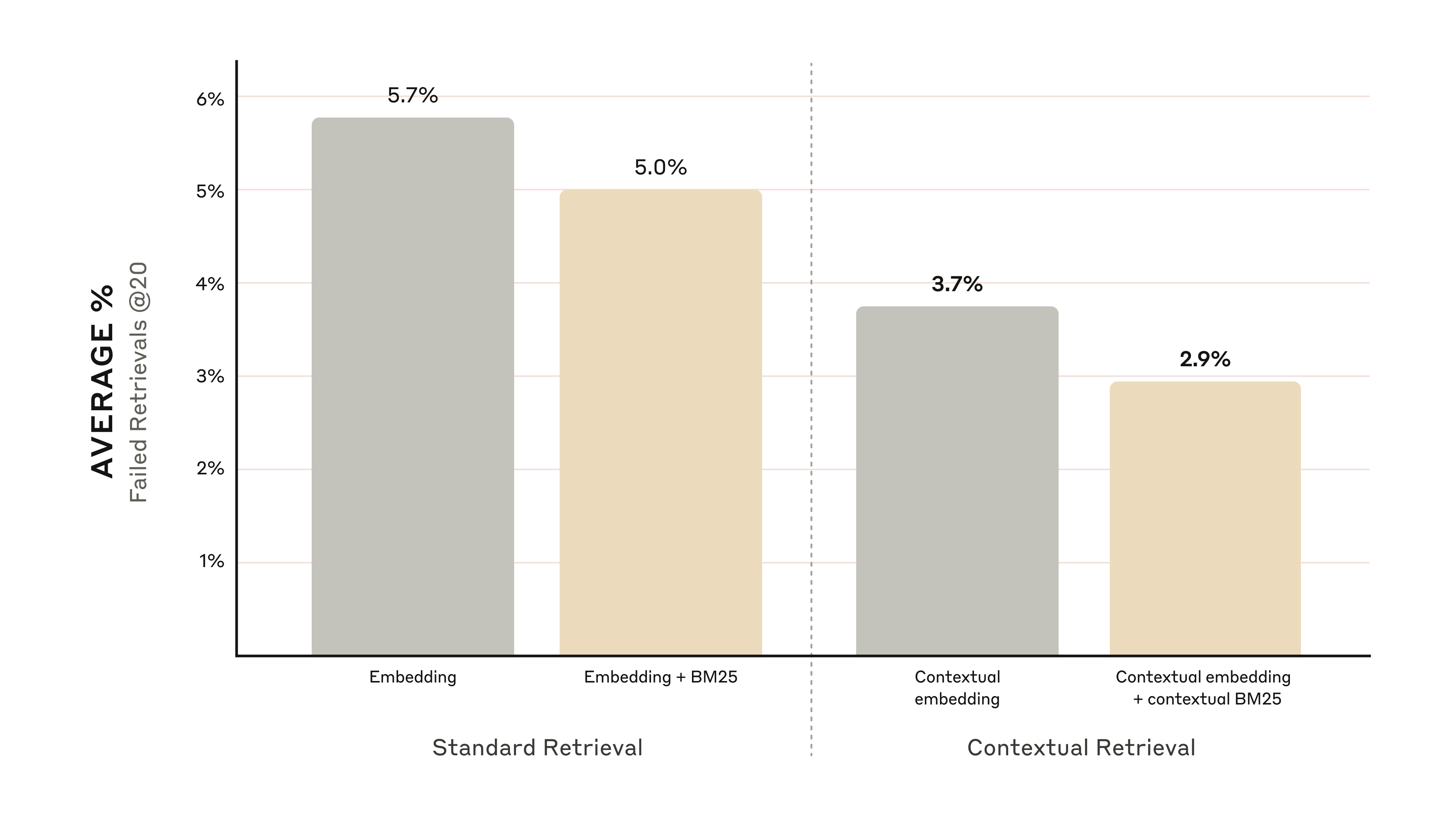 图5:Contextual Retrieval性能提升对比图(来源:Anthropic)
图5:Contextual Retrieval性能提升对比图(来源:Anthropic)
-
成本效益分析
- 一次性预处理成本:约$1.02/百万token
- 长期收益:检索准确率大幅提升
- ROI:通常在3-6个月内回本
-
技术实施细节
- 最优块大小:800-token是平衡信息密度和处理效率的最佳选择
- 检索策略:Top-20检索提供最佳的相关性和计算效率平衡
- 多模型策略:针对不同领域测试Gemini、Voyage等嵌入模型
- 提示缓存:利用Claude的提示缓存降低运行时成本
第三部分:构建有效Agent的六大工程原则
原则一:工作流优于纯Agent
根据Anthropic的实践,有效的Agent系统应该是结构化工作流和自主决策的有机结合:
- 五种核心工作流模式
- Prompt Chaining:任务分解成顺序步骤
- Routing:智能任务分发
- Parallelization:并行处理提升效率
- Orchestrator-Workers:主从协作模式
- Evaluator-Optimizer:迭代优化循环
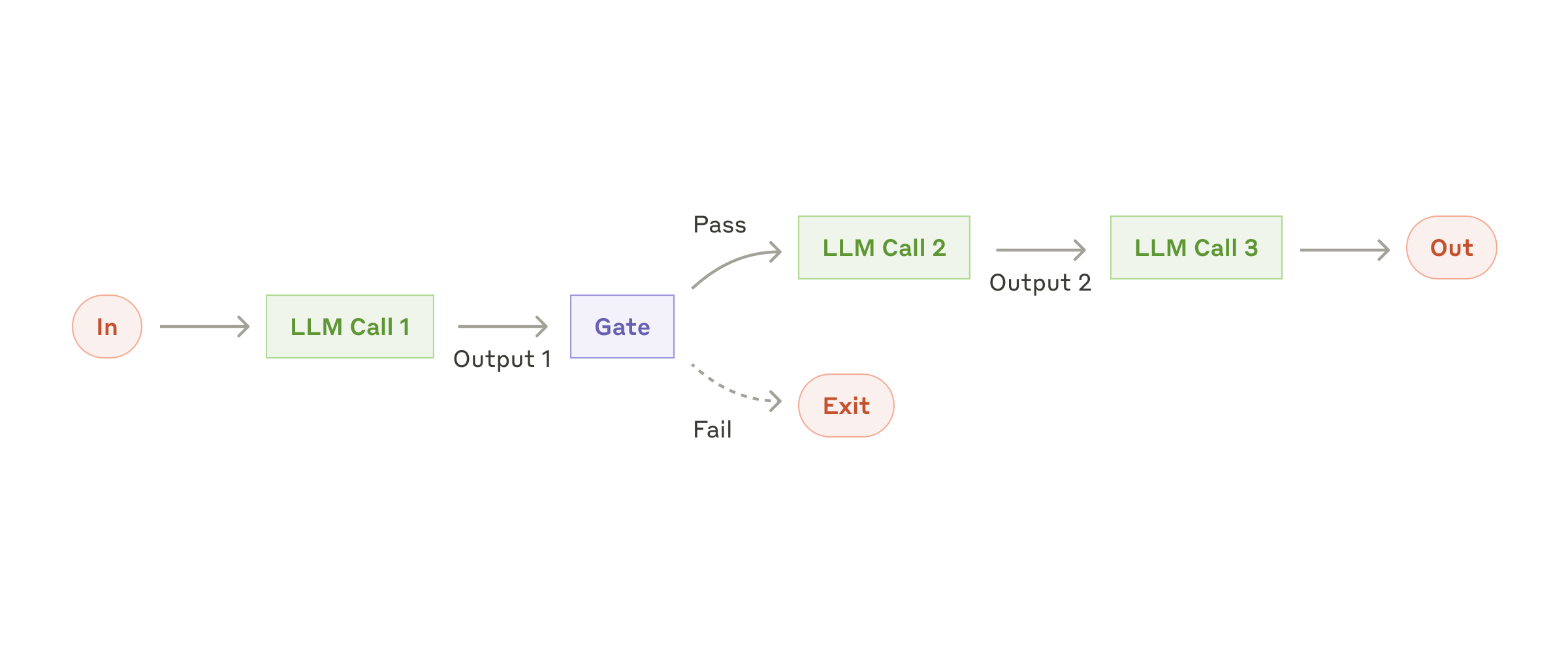 图2:五种核心Agent工作流模式对比(来源:Anthropic)
图2:五种核心Agent工作流模式对比(来源:Anthropic)
- 实践建议
- 先设计清晰的工作流
- 在关键节点引入Agent自主决策
- 保持系统的可预测性和可控性
原则二:并行化是性能的关键
Anthropic的多智能体系统通过并行化实现了90%的执行时间缩减:
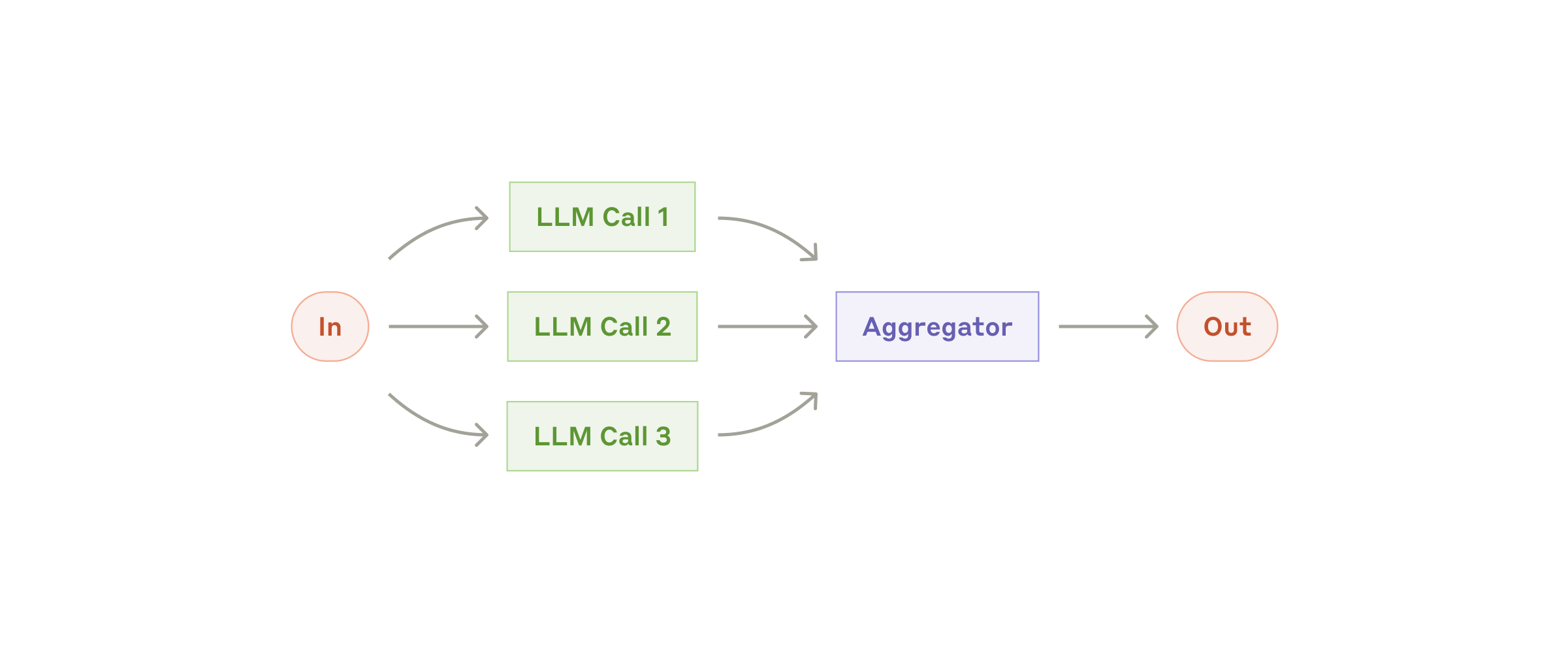 图6:串行vs并行处理效率对比(来源:Anthropic)
图6:串行vs并行处理效率对比(来源:Anthropic)
传统串行方式:
Task1 (3s) → Task2 (3s) → Task3 (3s) = 9秒
并行化方式:
Task1 ┐
Task2 ├─ 3秒
Task3 ┘
原则三:Context缓存的极致优化
还记得前面提到的KV-Cache吗?在多智能体系统中,这个更加重要:
- 全局缓存池:所有Agent共享的缓存资源
- 智能缓存策略:基于使用频率和重要性的动态调整
- 跨session持久化:长期任务的context保持
原则四:失败是最好的老师
多智能体系统中的错误处理哲学:
- 保留失败轨迹:每个Agent的失败尝试都是宝贵经验
- 集体学习机制:一个Agent的失败可以让其他Agent避免相同错误
- 渐进式改进:通过失败积累系统智慧
原则五:工具设计的Poka-Yoke原则
工具设计是Agent成功的关键,Anthropic提出了防错设计(Poka-Yoke)原则:
-
认知友好的设计
- 提供足够的”思考”token让模型推理
- 使用模型训练中熟悉的格式
- 最小化格式”开销”,避免浪费context
-
工具文档规范
# 好的工具设计示例 def search_documents(query: str, max_results: int = 10): """ 搜索文档库中的相关内容 Args: query: 搜索关键词 max_results: 最大返回结果数 Returns: List[Document]: 匹配的文档列表 Example: >>> search_documents("AI Agent架构", 5) [Document(title="Agent设计模式", content="...")] """ -
防错机制
- 参数验证和类型检查
- 明确的错误信息和恢复建议
- 沙箱环境测试和验证
原则六:动态工具管理
在多智能体环境下,工具管理变得更加复杂:
工具编排策略:
全局工具库:
- 所有Agent可访问的通用工具
- 统一的版本管理
专属工具集:
- 特定Agent的专用工具
- 基于任务的动态加载
权限控制:
- 细粒度的访问控制
- 安全隔离机制
原则七:注意力管理的艺术
多智能体系统中的注意力管理更像是一个交响乐团的指挥:
-
全局注意力协调
- Lead Agent维护全局优先级
- 动态调整各Agent的关注重点
-
局部注意力优化
- 每个Agent维护自己的todo list
- 通过复述机制保持专注
第四部分:2025年的技术趋势与最佳实践
趋势一:向量数据库与Context工程的深度融合
2025年,向量数据库不再只是存储embeddings的地方,而是成为了动态Context管理平台:
- 智能索引策略:基于访问模式的自适应索引
- Context版本控制:支持时间旅行和回滚
- 跨模态检索:文本、图像、代码的统一检索
趋势二:自适应Context压缩
随着任务复杂度增加,Context压缩技术变得至关重要:
class AdaptiveContextCompressor:
def compress(self, context, target_agent, task_type):
# 基于接收Agent和任务类型的智能压缩
importance_scores = self.calculate_importance(context)
compressed = self.selective_retention(context, importance_scores)
return self.format_for_agent(compressed, target_agent)
趋势三:Context即服务(CaaS)
企业级的Context管理正在向服务化演进:
- Context API:标准化的Context访问接口
- Context Marketplace:预训练的领域Context库
- Context Analytics:使用模式分析和优化建议
第五部分:企业级部署指南
成本控制策略
多智能体系统的成本主要来自三个方面:
关键成本指标:
-
Agent使用token是普通对话的4倍
-
多智能体系统token使用是普通对话的15倍
-
需要高价值任务才能证明计算成本合理
-
Token消耗
- 通过Context共享降低重复消耗
- 智能路由减少不必要的Agent调用
- 批处理优化API调用效率
-
计算资源
- 弹性伸缩的Agent池
- 基于负载的动态资源分配
- 边缘计算降低延迟
-
存储成本
- 分层存储策略(热-温-冷)
- 智能归档和清理机制
- 压缩存储优化
性能优化清单
- KV-Cache命中率 > 85%
- Agent间通信延迟 < 100ms
- Context压缩率 > 70%
- 并行化率 > 80%
- 错误恢复时间 < 5秒
安全与合规
多智能体系统带来了新的安全挑战:
- Agent间通信加密
- Context访问审计
- 敏感信息脱敏
- GDPR/CCPA合规
常见反模式警告
⚠️ 避免这些常见错误:
-
过度工程化
- 不要在没有证明需求的情况下增加复杂性
- 避免使用复杂框架而不理解底层机制
-
移除人工监督
- 完全自主的Agent存在风险
- 必须保留关键检查点和停止条件
-
工具文档不充分
- 缺乏清晰的使用示例
- 错误处理和接口设计不当
-
忽视停止条件
- 没有明确的任务完成标准
- 缺少防止Agent失控的机制
结语:Context工程的未来
2025年,我们正站在AI Agent产业化的关键节点上。多智能体系统不是简单的技术升级,而是认知架构的根本变革。
成功的关键在于:
- 深刻理解Context的本质——它不仅是信息,更是Agent的”认知基础设施”
- 掌握工程化方法——从实验室到生产环境的系统性方法论
- 持续优化迭代——基于真实场景的不断改进
正如软件工程定义了互联网时代,Context工程将定义AI时代。在这个Multi-Agent协作成为常态的未来,掌握Context工程不仅是技术优势,更是企业数字化转型的核心竞争力。
记住:优秀的Agent靠算法,卓越的Agent靠Context。
本文基于Anthropic工程团队的最新实践,结合2025年行业发展趋势,为构建企业级多智能体系统提供实战指南。在AI重塑商业的时代,让我们一起掌握Context工程的精髓,构建真正智能的Agent系统。